Despite remarkable advances in large language models (LLMs), they often struggle to consistently provide accurate solutions for complex logical inference tasks. To address the limitations, Andrew Chi-Chih Yao and Yang Yuan’s research team recently proposed a “Cumulative Reasoning (CR)” framework, which has significantly boosted the accuracy rate by achieving 98% precision in logical inference tasks and realized 43% relative improvement in the most challenging level 5 MATH problems.
Previous approaches, such as the Chain-of Thought (CoT) that “prompts the model to provide stepwise solutions” and the Tree-of-Thought (ToT) that “models the thinking process as a thought search tree”, have overlooked the site for storing intermediate results. The CR framework has been designed to fill the gap by decomposing unmanageable tasks into atomic steps and maintaining a storage site for intermediate results.
Specifically, the CR algorithm utilizes three distinct types of LLMs: the proposer, verifier, and reporter. When the proposer model suggests next steps based on the given context, the verifier model scrutinizes the proposed steps and then adds validated steps to the ongoing reasoning context. Meanwhile, the reporter model evaluates when the iterative and cumulative reasoning process can be completed.
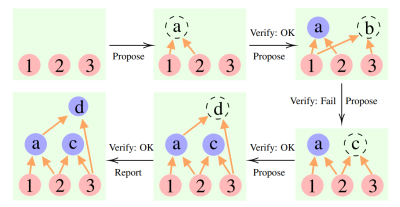
Figure 1. An Illustration of CR Reasoning for a 3-premises problem
This framework has been tested on several datasets, including FOLIO wiki and AutoTNLI for logical inference, Game of 24 for arithmetic reasoning, and the MATH dataset for complex mathematical problems. The results show that CR framework consistently surpassed CoT and CoT-SC with a performance margin spanning up to 8.42% on FOLIO wiki and achieved a relative improvement of 9.3% in the framework of the AutoTNLI dataset. It also outperformed ToT by a large margin of 24% in the Game of 24 and realized a substantial relative improvement of 43% in the most difficult problems, classified as Level 5, on the MATH dataset.
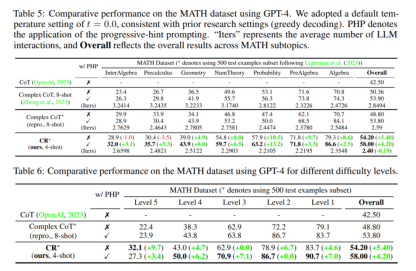
Figure 2. Results for various reasoning approaches on MATH dataset
“As the cumulative method continuous to be refined, in the near future, we may expect to have AI mathematicians who can solve complex math problems independently and precisely,”co-author Yifan Zhang said. Yet, there is still a long way to go. Zhang added, “The realization of AI scientists is faced with myriads of obstacles, such as the need for reliable verification of LLM-generated results and the expansion of context length to tackle increasingly complex problems.”
The corresponding authors of the paper are Tsinghua IIIS Dean Andrew Chi-Chih Yao and Assistant Professor Yang Yuan. The co-first authors are Yifan Zhang and Jingqin Yang. This research has been collected in Cornell University arXiv.
Paper Link: https://arxiv.org/abs/2308.04371
Github: https://github.com/iiis-ai/cumulative-reasoning
(reported by Yueliang Jiang)
