姚期智先生曾说,在ChatGPT之后,人工智能研究的下一个重要目标,是让有多重感知能力的机器人,在不同的环境下能够自主学习新技能。近期,清华大学交叉信息院高阳研究组提出ViLa算法(全称Robotic Vision-Language Planning),通过利用GPT-4V这类视觉语言模型,使机器人能够在复杂环境中主动进行任务规划。
1. 神奇的薯片在哪里?

当你午后小憩时想吃薯片,便说:“请帮我倒一罐薯片。” ViLa算法立刻开始行动。它发现薯片不在视线中,就基于对当前环境的视觉观测,并结合对已有知识的推理打开了柜门,成功找到薯片到并帮你倒进了盘子。

晚饭时,你突然有了品尝日料的灵感,于是说:“请按照图片帮我摆一盘寿司。”ViLa算法迅速按照要求将虾寿司、鲑鱼寿司、金枪鱼寿司依次排列。
拥有这样一台机器人的梦想已不再遥远。清华大学交叉信息院学生在助理教授高阳、弋力的指导下近期提出了ViLa算法,这一算法基于视觉语言大模型,能够大幅提升机器人对物理世界的理解力,并有效增强机器人的自主规划能力。ViLa不仅可以在现实世界中执行上述一切任务,甚至可以实现更为复杂的任务。
2. ViLa算法的逻辑
ViLa 算法主要采用视觉语言大模型(如 GPT-4V),将高级抽象指令分解为一系列低级可执行技能。在实际应用中,ViLa算法能够基于人类给出的语言指令和自身对当前场景的视觉观测图像,通过链式思维推理来理解环境场景,随后自主规划步骤。

接着,这些步骤逐步执行。已执行的步骤将被添加到已完成的计划中,在动态环境中形成一个闭环规划方法。

对于为何从视觉语言大模型(VLM)入手,研究团队表示,相较于文字语言,图像在呈现复杂场景时能够“一图胜千言”。而且,如今的 VLM 在图像和语言两个模态上都展现出前所未有的理解和推理能力,而且GPT-4V 由于经过大规模互联网数据的训练,也展现出了卓越的多样性和极强的泛化能力,契合研究者们对机器人在复杂场景中处理多元任务的期待。
3. 聪明的ViLa和实验们
随后研究者们通过大量有趣的实验证明,ViLa算法在(1)深刻理解视觉世界中的常识、(2)多模态目标指定、(3)视觉反馈三个方面的表现皆优于基线算法。
ViLa算法能深刻理解视觉世界常识
ViLa算法对视觉世界中常识的深刻理解可分为对空间布局和物体属性这两个关键方面的感知能力。
空间布局感知指的是准确识别场景中物体定位、位置关系的能力。比如,在“拿空盘子”的任务中,ViLa知道需要在举起蓝色的盘子前,先把上面的苹果和香蕉移走。而作为参照的基线方法则忽视了盘子上的物体,直接给出“拿起蓝色盘子”的错误指令。

物体属性感知包括对形状、颜色、材质、功能等的认知。比如,ViLa能够根据美术课场景中的彩纸,推断出上课所需的工具是剪刀,并指导机械臂将螺丝刀、水果刀等危险物品放入收纳盒中。而基线方法则忽视了桌上的剪纸和美术课这一特定场景,认为剪刀也是危险物品,选择将其移走。

同理,在 “挑选新鲜水果” 任务中,ViLa 可以准确地挑选出新鲜且完整的水果。而基线方法则认为剥了一半的橘子和腐烂的香蕉都是完整且新鲜的水果。

ViLa算法能够进行多模态目标指定
ViLa 不仅能够执行语言指令,还能够以多种形式的图像作为目标,甚至利用语言和图像的混合形式来定义目标。
|
 |
|
 |
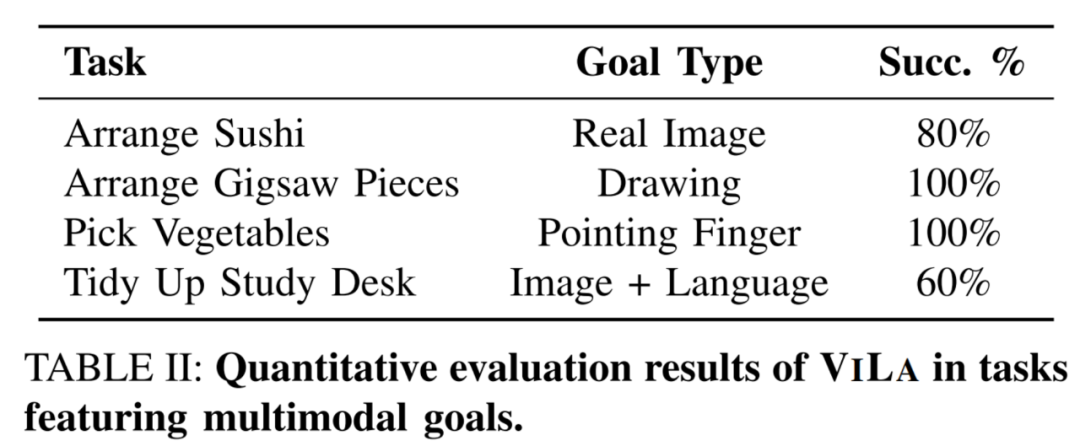
视频中的四个任务分别表明:
ViLa算法可以将真实图片作为目标。
比如,在左上角的“寿司摆盘”的任务中,ViLa将真实图像作为目标,将寿司按顺序排列。
ViLa算法可以将抽象图片(如小孩的画,草稿等)作为目标。
在右上角的视频中,ViLa算法能够识别抽象画作,并进行拼图。
ViLa算法可以将语言和图像的混合形式作为目标。
左下角的视频显示,ViLa算法可以处理给定的图像目标和要求“调换两个物体位置”的语言命令,重新排布物品位置。
ViLa 算法可以发现图片中手指指着的位置,并将其作为实际任务中的目标位置。
研究团队在这四个任务上进行了定量实验。如图所示,ViLa 在所有任务中均表现出了强大的识别多模态目标的能力。
ViLa算法能够进行视觉反馈
ViLa算法还能够以直观、自然的方式有效利用视觉反馈,在动态环境中实现鲁棒的闭环规划。
 |
 |
 |
 |
在左上 “堆木块” 任务中,ViLa 检测出了执行基本技能时的失败情况,于是重新执行了一遍基本技能。
在左下 “放薯片” 任务中,ViLa 意识到了执行过程中人的干扰。
在右上 “找猫粮” 任务中,ViLa 可以不断地打开抽屉 / 柜子来寻找猫粮,直到找到目标。
此外,ViLa 可以完成需要人机交互的任务,在右下的视频中能够等待人握住可乐罐之后才松开夹爪。
作者团队在这四个任务上进行了定量实验。如图所示,通过自然地结合视觉反馈,闭环控制的 ViLa 的表现显著强于开环控制。

模拟环境实验
在模拟环境中,ViLa 可以按照高级语言指令的指示,将桌子上的物体重新组织成特定的排列。
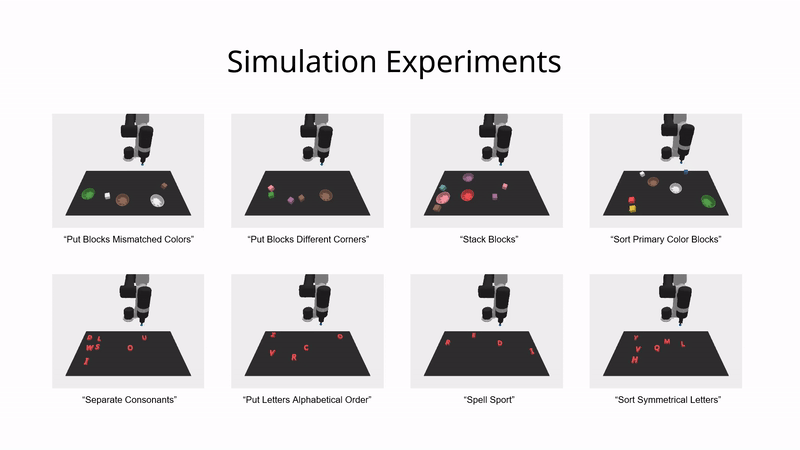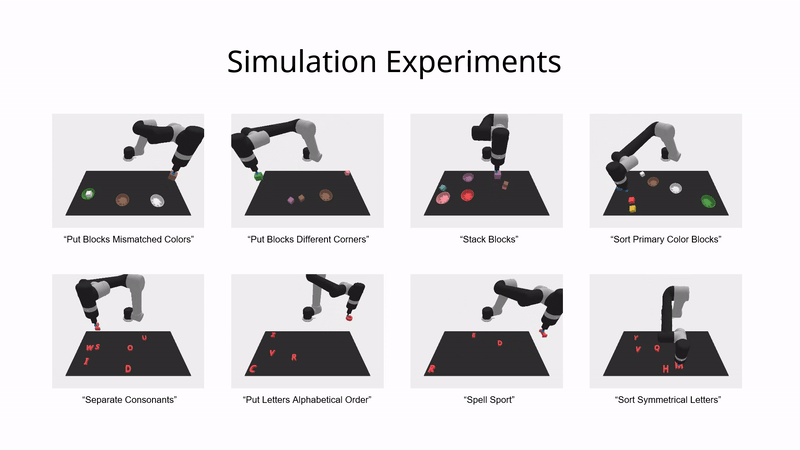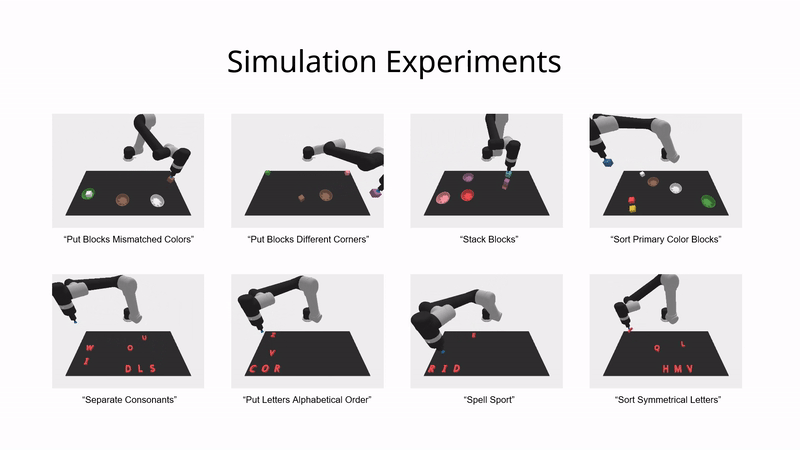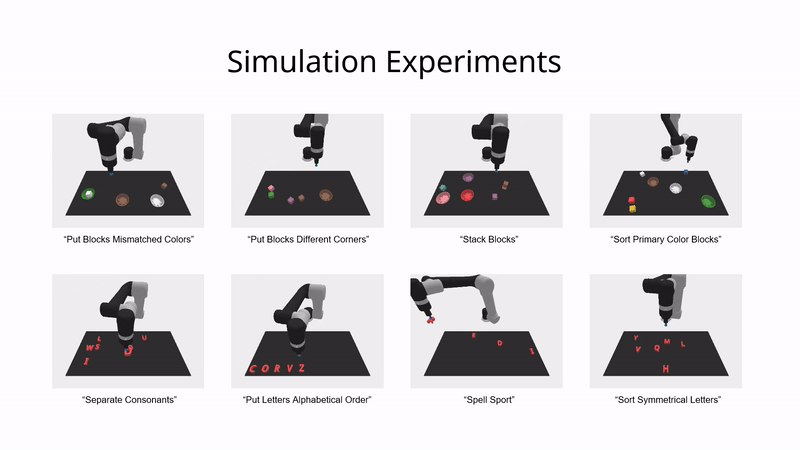
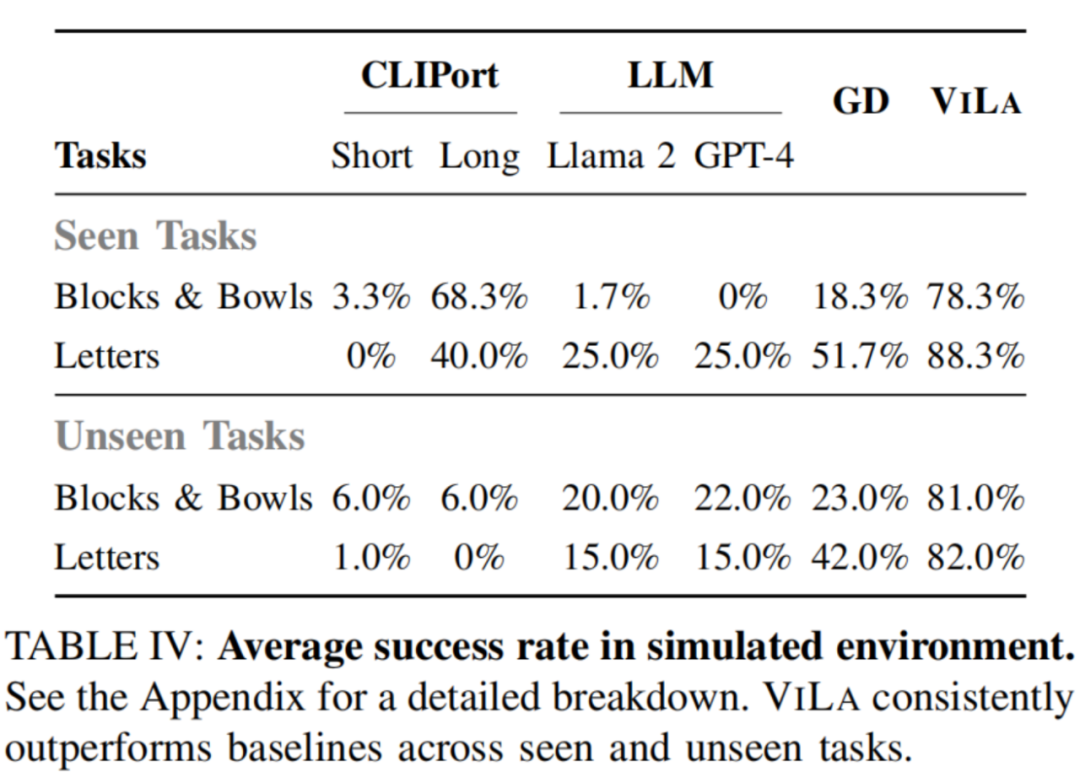
如图所示,ViLa 在模拟环境中的表现也显著超过了基线方法。
4. ViLa算法的未来
对于ViLa算法的发展,论文第一作者胡英东同学表示:“我们的愿景是赋予人工智能具体的形态,在实际生活中协助人类。而ViLa算法可以说是在这个大方向上迈出了一小步,令机器人在现实世界能够展现强大的任务规划能力。我们期待这一技术能在未来继续发展成为机器人系统中更为通用的任务规划方法。”
研究组简介
该论文《Look Before You Leap: Unveiling the Power of GPT-4V in Robotic Vision-Language Planning》来自清华大学交叉信息院高阳研究组,弋力助理教授参与指导。论文共同第一作者为清华大学交叉信息院2021级博士生胡英东、2020级本科生林凡淇,通讯作者为高阳助理教授,其他作者还包括弋力助理教授、2020级博士生张彤。
论文链接:https://arxiv.org/pdf/2311.17842.pdf
项目主页: https://robot-vila.github.io/
采编:姜月亮
校对:胡英东
审核:吕厦敏
