自动驾驶技术作为新质生产力的典型代表,已成为全球新一轮科技革命的一大制高点。2024年初,特斯拉FSD V12正式发布,其以纯视觉、端到端神经网络为核心的自动驾驶方案展现出了出色的驾驶能力,引发业内强烈关注。
面对大洋彼岸释放的“新鲶鱼”,近期,清华大学交叉信息院赵行老师研究组MARS Lab与理想汽车合作,提出了一种基于大模型的高阶自动驾驶的全新方案DriveVLM。DriveVLM以视觉语言大模型为基础,并与端到端模型实现双系统,在复杂和驾驶场景中表现出色,是首个部署上车的自动驾驶大模型。该成果论文近日收录于CoRL 2024。
论文链接:https://arxiv.org/abs/2402.12289
项目链接:https://tsinghua-mars-lab.github.io/DriveVLM/
1. DriveVLM模型架构
与传统自动驾驶系统“感知-预测-规划”的流程组件不同,DriveVLM 依托思维链(Chain-of-Though,CoT)组合串联场景描述(scene description)、场景分析(scene analysis)和分层规划(hierarchical planning)三个关键模块。 相比于传统“感知-预测”模块对于限定类别的障碍物进行检测并且只预测障碍物的未来轨迹,DriveVLM识别并分析驾驶环境中的关键物体,包括那些非常规或少见的对象,场景分析模块能够深入分析物体的静态属性、动态状态和特殊行为,从而实现更全面的场景理解与分析。此外,DriveVLM还通过分层规划,从多个维度对自车未来轨迹进行逐步规划,能够提供更丰富的预测。
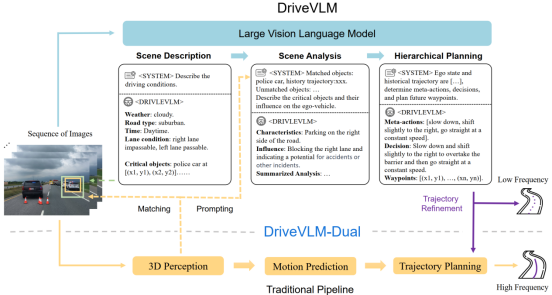
(1) 场景描述
其中,场景描述模块的主要功能是用语言描述驾驶环境并识别场景中的关键物体。驾驶环境包括天气、时间、道路类型、车道线等指标,而关键物体特指当前驾驶场景中最有可能影响自动驾驶决策的物体。
研究组为提升大模型场景理解和规划的准确性,不仅提出了新的评估指标,还构建了模型内部数SUP-AD数据集,进行了全面的数据挖掘和标注。实验表明,由于基于大量的预训练数据,DriveVLM相较于传统3D感知和目标检测器,能够更好地识别非常见动物、路面杂物等长尾关键物体。
(2) 场景分析
传统端到端自动驾驶方案中预测模块一般只输出物体的未来轨迹,来辅助后续规划模块进行决策。得益于视觉语言大模型,DriveVLM将关键物体的特征分为静态属性(Cs)、运动状态(Cm)和特殊行为(Cp)三个方面,对驾驶场景进行更加全面的分析。
具体来看,静态属性描述了物体固有属性,比如道路标志中的符号、卡车车身长度等;运动属性描述物体在一段时间内的运动状态,包括位置、方向、动作等;特殊行为指某些专属于该物体的可能影响自动驾驶的特定行为或手势,比如交警指挥交通的手势,面前人挥手示意等。
DriveVLM模型会自适应地输出关键物体在这三方面的属性,并在分析完场景中所有关键物体后,提供当前驾驶场景的总结,辅助后续的分层及规划模块。
(3) 分层规划
DriveVLM提出了一种逐渐递进地层级式规划,依次推理对应自车未来驾驶决策的元动作、决策描述、轨迹点三种规划目标。
“元动作”指的是驾驶决策的基本单位,研究组将元动作归为17种,包括等待、加速、向左/右变道等。基于此,“决策描述”提供更加详细的多维描述,通常包含动作A、主体S、持续时间D这三个基本元素。例如,决策描述可输出“等待(A)行人(S)通过街道,然后(D)开始加速(A),并且汇入右侧车道(S)”。在前两部的基础上, “轨迹点”预测将对物体未来固定时间间隔t时刻的位置进行假设。通过分层及设计,DriveVLM由易到难逐步输出决策规划,并将对应的轨迹点传送至规控模块进行进一步的细化和完善。
2. DriveVLM-Dual
尽管视觉语言大模型在识别长尾物体和理解复杂场景方面表现优越,但由于巨大的参数量,其通常比传统自动驾驶系统有更高的延时,阻碍自动驾驶系统的快速实时反应。
为解决这一问题,研究组参考人脑处理信息的双通路模型(Dual-Routes Models of Information Processing)指出,大模型不仅应依赖逻辑推理“慢系统”来处理复杂的驾驶情况,也应能运用下意识“快系统”处理常见的、简单的驾驶情况。于是,研究组提出了Drive VLM-Dual System,模拟人脑开车时的“快系统”+“慢系统”,将DriveVLM的优势与传统自动驾驶系统相结合,实现了强大的场景理解和实时推理速度。
3. 构建数据集
在人工智能的三驾马车中,数据是生产原料,算力是基础设施,算法则是大模型的逻辑表示。为提升数据质量和DriveVLM大模型准确度,研究组提出了一个全面的数据挖掘和标注流水线,并构建了包含超40个场景类别的自动驾驶数据集SUP-AD(scene understanding for planning- autonomous driving)。
数据挖掘和标注方面,研究组首先从海量自动驾驶数据中挖掘长尾目标并收集挑战性场景样本数据,随后选择每个场景的关键帧并进行相应场景的信息标注。
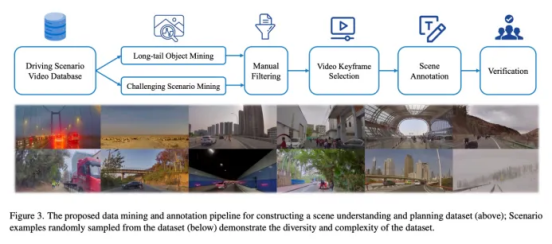
为便于场景标注,研究组还开发了一个视频标注工具,能够比较方便的针对特定标注内容进行对应的标注和检查。某个场景关键帧的标注结果如下图所示。

4. 实验检验
在大规模城市场景驾驶数据集nuScenes的检验中,DriveVLM以Qwen-VL作为骨干,相较于GPT-4V、CogVLM和Lynx等其他开源VLM实现了最佳性能。DriveVLM-Dual 与 VAD 配合时,在 nuScenes 规划任务上取得了最先进的性能。充分证明了该模型在简单和复杂场景中的应用潜力。
目前,研究组已与理想汽车合作,将DriveVLM-Dual双系统方案部署在理想的Max车型上并做了实际场景的测试。理想的Max车型中一颗OrinX跑端到端系统,一颗OrinX跑DriveVLM,两个系统并行运行。若遇到长尾场景,慢系统(VLM)介入快系统。这一方案目前在复杂施工、夜间行车等实景测试中效果显著。
尽管实验结果已展现出大模型赋能自动驾驶的效果,论文作者辜俊儒指出,目前落地应用的仍然是较为简单的场景,而诸如超车、躲避小动物、应对树木突然倒塌等更为复杂的场景有待进一步的探索。
4. 未来展望
在中国,百度、华为、阿里、“蔚小理”等企业持续探索自动驾驶新方案,萝卜快跑、小马智行等目前走在商业化示范应用的前列;在美国,特斯拉、Waymo等企业加速实车落地应用。在不同技术路线的角逐中,视觉语言大模型赋能自动驾驶这一新方案逐步进入快车道,为自动驾驶行业实现Level3-5水平提供创新路径。
未来,研究组希望进一步提升DriveVLM模型的实时性和复杂场景理解与分析能力,通过在专有数据上持续训练,以及对模型结构作出更适合自动驾驶领域的改进,以提升在更多变化复杂的驾驶环境上的表现性能。
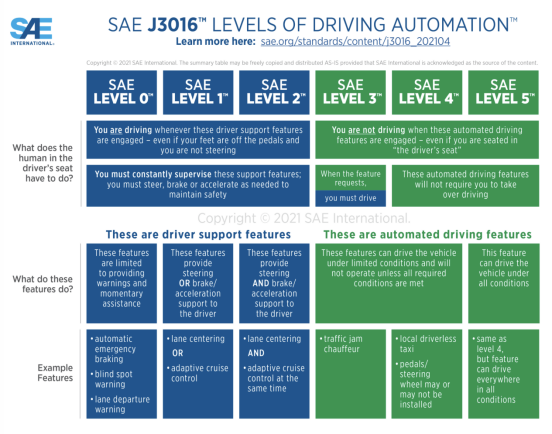
图|国际自动机工程师学会(Society of Autonomous Engineers,SAE)将自动驾驶分为六个等级,其中Level 0至Level 2属于辅助驾驶阶段,而Level 3至Level 5属于自动驾驶阶段。
研究组概况
该论文共同第一作者为清华大学交叉信息院2023级博士生田晓宇、2021级博士生辜俊儒、2023级博士生刘毅成,论文通讯作者为赵行助理教授,其他论文作者还包括来自理想的研究者李佰霖、王洋、赵志勇、詹锟、贾鹏、郎咸朋。
访谈、视频、编辑 | 姜月亮
审核 | 吕厦敏
