近日,清华大学交叉信息研究院曾坚阳研究组在《细胞》子刊《细胞·系统》(Cell Systems)发表题为“Analysis of Ribosome Stalling and Translation Elongation Dynamics by Deep Learning”(《利用深度学习分析核糖体停滞现象与蛋白质翻译动态》)的研究论文,首次利用深度学习技术对蛋白质翻译的动态过程进行建模。该成果也被第21届国际计算分子生物学大会(RECOMB 2017)接收,并作为计算生物学新兴研究方向的代表性工作被邀请做大会论文口头报告。该工作提出了一种全新的基于高通量测序技术的深度学习计算框架,并以此揭示了蛋白质翻译这一基本生物过程的调控机制。
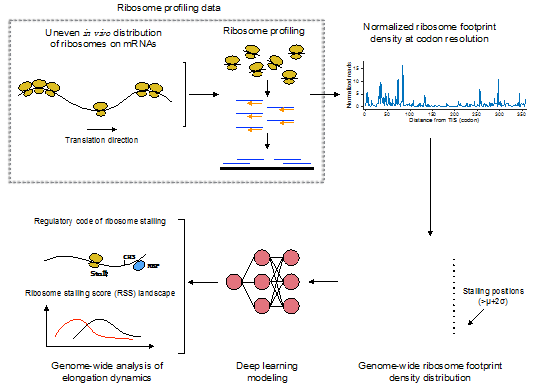
蛋白质翻译是遗传信息从其携带者DNA到执行者蛋白质传递的关键一环,也是分子生物学中心法则的核心环节。在蛋白质翻译的过程中,一种名为核糖体(ribosome)的细胞器会沿着信使RNA链,按照遗传密码子的对应法则依次将核苷酸序列翻译成氨基酸序列,继而形成多肽链。近年来,生物学家们通过各种高通量测序技术测量发现,蛋白质翻译的过程是动态变化的,其中大量存在一种核糖体翻译停滞(ribosome stalling)的现象,这一现象与翻译过程中的蛋白质折叠和定位等一系列重要过程有关。
作为该领域的一项突破性进展,曾坚阳研究组首次提出了一种基于机器学习的计算框架来研究核糖体停滞现象的调控机制和功能,并成功利用深度学习技术实现了对蛋白质翻译过程中核糖体翻译停滞的精确预测。传统的观点认为,mRNA序列信息只是通过密码子表编码氨基酸序列,而本工作首次对mRNA序列中编码蛋白质翻译的调控信息进行建模。该模型仅以信使RNA的一级序列作为特征输入,没有整合其他的生物学特征。进一步地,研究人员基于深度学习自动提取的隐藏特征以及模型精确的预测结果,对调控核糖体翻译停滞的各种因素以及该现象的生物学功能进行了系统性的分析,在验证前人研究成果的同时,提出了许多新的假设,为进一步探究蛋白质翻译的动态特征打下了坚实的基础。
国际计算分子生物学大会(RECOMB)是计算生物学领域的两大顶级会议之一,该会议历年平均录用率约为20%。 论文共同第一作者为交叉信息研究院博士生张赛(目前在美国斯坦福大学进行博士后研究)、药学实验班博士生胡海林(目前为医学院在读博士生)以及本科生周镜天(目前在美国加州大学圣地亚哥分校攻读博士学位),通讯作者为曾坚阳助理教授。该项工作与美国加州大学河滨分校的姜涛教授合作完成。《细胞·系统》(Cell Systems)是隶属于Cell出版集团新兴交叉学科期刊,其定位于收录系统生物学和定量生物学研究的高水平文章。作为国际知名顶级期刊《细胞》(Cell)的子刊,《细胞·系统》建刊两年以来,已经在国际上取得了相当广泛的影响力。
此外,本文的姊妹工作,TITER: predicting translation initiation sites by deep learning(《TITER: 利用深度学习预测蛋白质翻译起始位点》),已于2017年7月在国际计算生物学知名期刊《生物信息学》(Bioinformatics)在线发表,同时被国际分子生物学智能系统大会(ISMB 2017)收录为大会口头报告。该研究利用深度学习技术预测转录组中的翻译起始位点,首次将预测范围扩大到了转录组中所有种类的翻译起始位点,并对翻译起始位置的序列特征、调控功能、突变效应做了深度解析。该项工作共同第一作者为张赛和胡海林同学,并与姜涛教授及医学院公共健康研究中心张磊教授合作完成。这两项工作的完成为人类解码蛋白质翻译过程提供了重要信息。
曾坚阳研究组是国内较早将深度学习应用到基因组学数据分析的研究组之一。本系列工作得到中国国家自然科学基金、美国国家科学基金会(NSF)和清华大学结构生物学高精尖创新中心的经费支持。
相关论文链接:
http://www.cell.com/cell-systems/fulltext/S2405-4712(17)30337-X
https://doi.org/10.1093/bioinformatics/btx247
